ElevenLabs Documentation
How ElevenLabs works
ElevenLabs provides AI voice infrastructure: text-to-speech, speech-to-text, voice cloning, conversational agents, and generative audio. You can use it in four ways, suited to different audiences.
ElevenCreative is a no-code web application where creators, producers, and editors generate voiceovers, music, dubs, and studio projects directly in the browser.
ElevenAgents is the platform for designing and operating conversational voice agents, with a visual builder for non-technical users and full programmatic control for developers.
ElevenAPI exposes every capability as a REST interface with official Python and TypeScript SDKs, so developers can embed voice into their own applications and workflows.
Reception AI is a ready-to-deploy AI phone receptionist for small and medium businesses that answers calls, books appointments, and manages day-to-day operations from a single dashboard.
Concepts
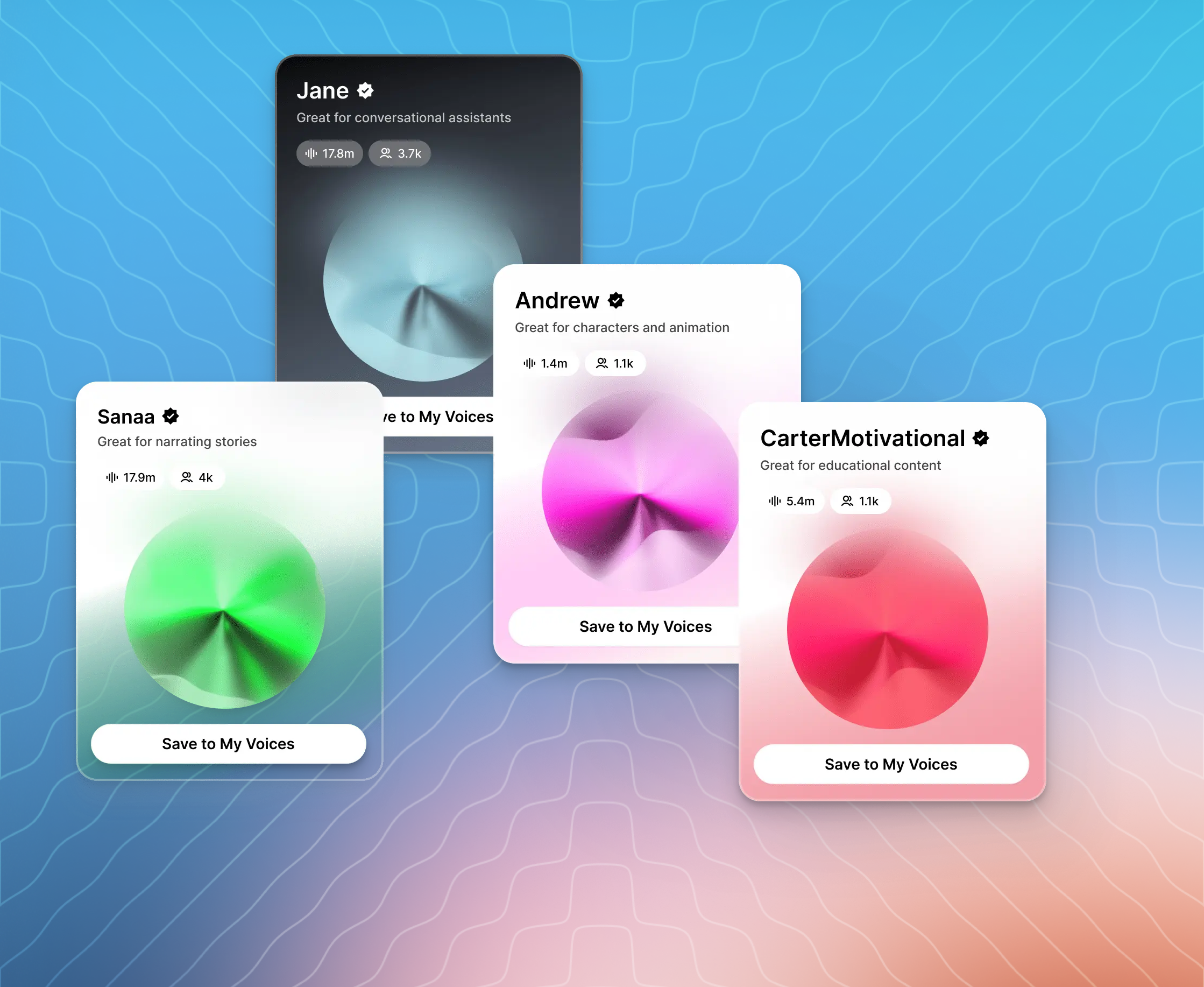
Voices are the speech persona used in audio generation. Each voice has a unique ID — for example, JBFqnCBsd6RMkjVDRZzb — that you select in the dashboard or pass in API requests. ElevenLabs maintains a library of 10,000+ voices. You can also clone a voice from an audio recording or generate one from a text description.
Models control the quality, latency, and language coverage of generated audio. eleven_v3 produces the most expressive output across 70+ languages. eleven_flash_v2_5 targets real-time use at ~75ms latency. Each capability — speech-to-text, music, sound effects — has its own dedicated model.
Credits are the unit of consumption shared across every product. Text-to-speech costs one credit per character of input text. Other operations are charged per second of audio processed. Credits reset monthly and unused credits roll over for up to two months. See pricing for a full breakdown.
Choose your path

Meet the models
Our most emotionally rich, expressive speech synthesis model
Lifelike, consistent quality speech synthesis model
Our fast, affordable speech synthesis model
State-of-the-art speech recognition model
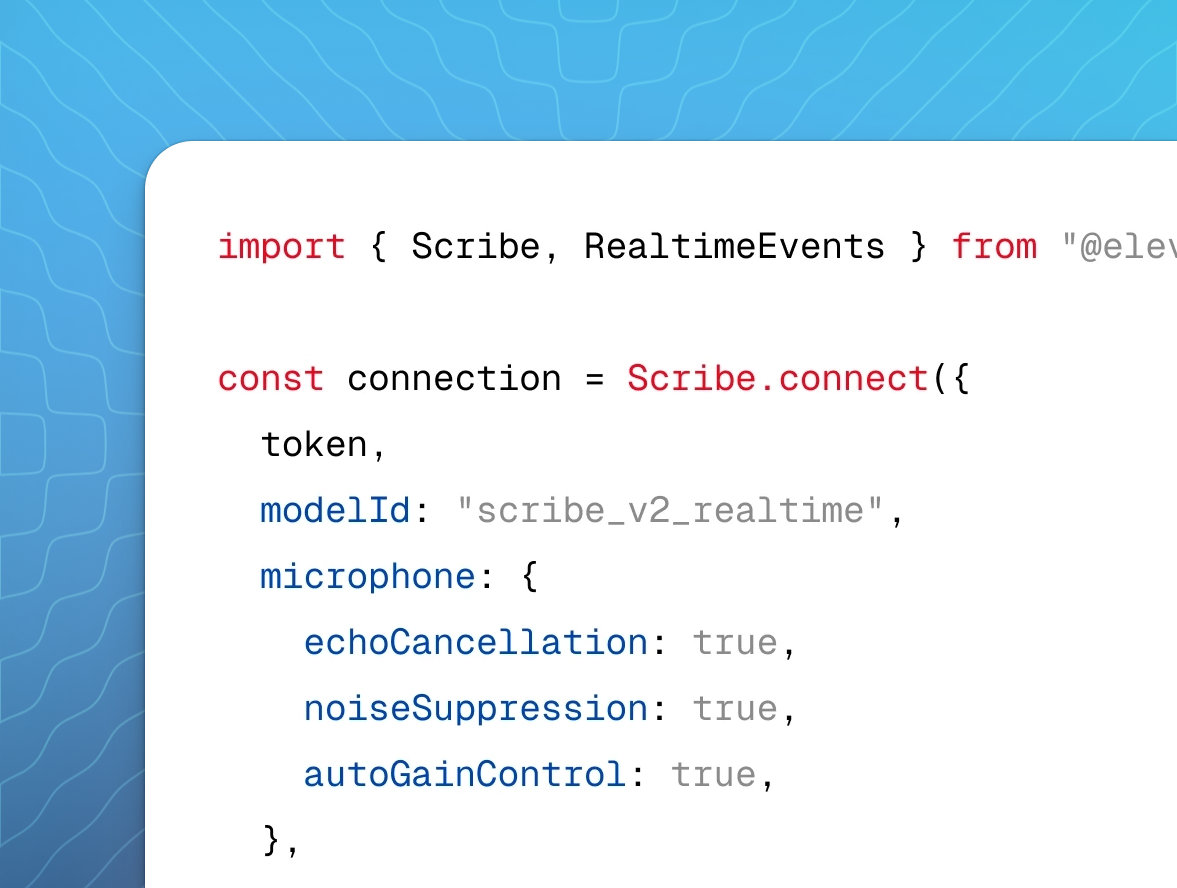
Real-time speech recognition model
Browse by capability
Convert text into lifelike speech
Transcribe spoken audio into text
Generate music from text
Create natural-sounding dialogue from text
Generate images and videos from text
Modify and transform voices
Isolate voices from background noise
Dub audio and videos seamlessly
Create cinematic sound effects
Clone and design custom voices
Transform and enhance existing voices
Align text to audio
Add voice to anything
Deploy intelligent voice agents